An introduction to Transfer Learning

Transfer Learning
1. What is Transfer Learning?
- Situation:
- We have a small dataset that can’t be used to train a deep learning model from scratch.
- There exists a model that was trained on a similar task to the one you want to solve.
- Solution: Use the pre-trained model as a starting point for your model.
Definition: Transfer learning is a machine learning method where a model developed for a task is reused as the starting point for a model on a second task.
Transfer learning only works in deep learning if the model features learned from the first task are general.
“In transfer learning, we first train a base network on a base dataset and task, and then we repurpose the learned features, or transfer them, to a second target network to be trained on a target dataset and task. This process will tend to work if the features are general, meaning suitable to both base and target tasks, instead of specific to the base task.”
- This form of transfer learning used in deep learning is called inductive transfer. This is where the scope of possible models (model bias) is narrowed in a beneficial way by using a model fit on a different but related task.
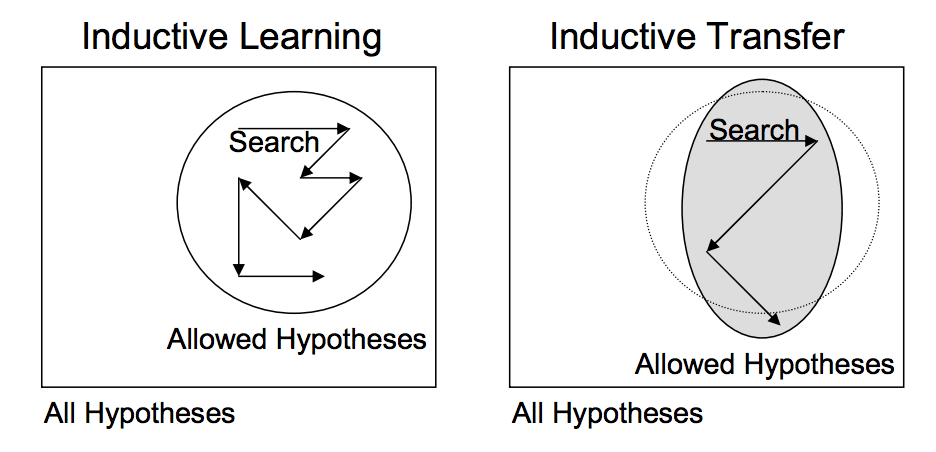
Inductive Learning vs Inductive Transfer
- In the above image: instead of searching the entire space of possible models, our spaces is narrowed to just those models that fit the first task. This is beneficial as it is a smaller search space from which to find a good or optimal model for the second task.
2. How to Use Transfer Learning?
- Two common approaches of using Transfer Learning:
- Use the pre-trained model as a fixed feature extractor
- Fine-tune the pre-trained model

Transfer Learning Process
2.1. Feature extractor
The pre-trained model is used as a feature extractor for the dataset of interest.
After obtaining a pre-trained model, we remove the last fully connected layer of the pre-trained model and add a new fully connected layer with random weights. We train the new fully connected layer on our dataset.
The pre-trained model is used as a fixed feature extractor. This means that the weights of the pre-trained model will not be updated during training.
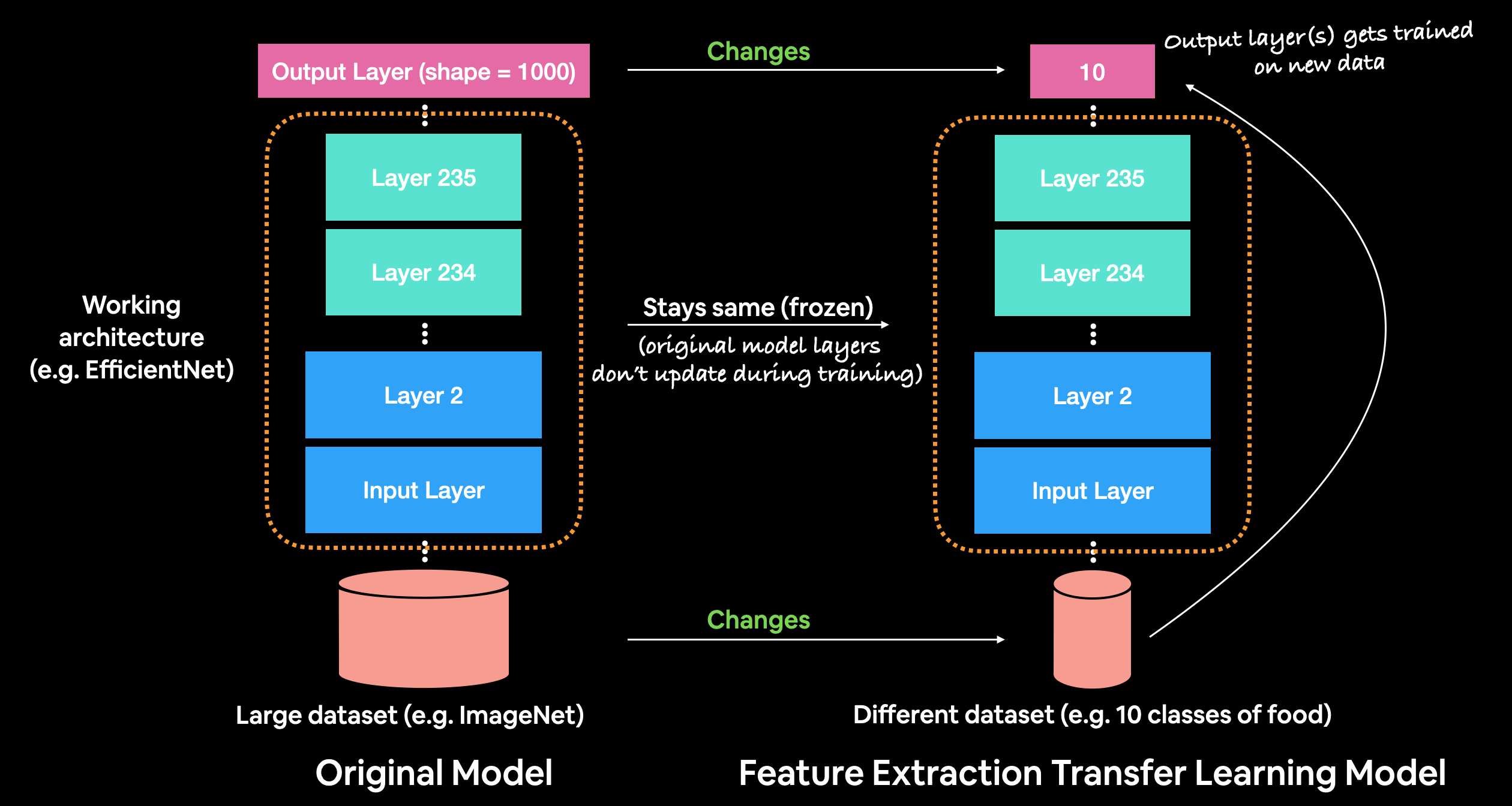
Feature Extractor Example
- In short, we have the following workflow:
- Take layers from a previously trained model.
- Freeze them, so as to avoid destroying any of the information they contain during future training rounds.
- Add some new, trainable layers on top of the frozen layers. They will learn to turn the old features into predictions on a new dataset.
- Train the new layers on your dataset.
2.2. Fine-tuning
Fine-tuning is the next optional step after feature extraction, which consists of unfreezing the entire pretrained model above (or part of it), and re-training it on the new data with a very low learning rate. This can potentially achieve meaningful improvements.
We remove the old fully connected layers of the pre-trained model and replace them with new fully connected layers with random weights.
- Then, we have 2 periods of training:
- First period:
- Because the weights of new fully connected layers are random while the weights of the pre-trained model are good, we freeze the weights of the pre-trained model and train the new fully connected layers first.
- We train the new fully connected layers until the model learns something and move to the second period.
- Second period:
- We unfreeze the weights of the pre-trained model and train the whole model.
- We can unfreeze all the layers of the pre-trained model or just some of them based on time and resources.
- First period:
- For example of fine-tuning a VGG16 pre-trained model:
| Add new layer | First period | Second period |
|---|---|---|
 |  |  |
3. When to Use Transfer Learning?
- 3 benefits of using transfer learning:
- Higher start: The initial skill (before refining the model) on the source model is higher than it otherwise would be.
- Higher slope: The rate of improvement of skill during training of the source model is steeper than it otherwise would be.
- Higher asymptote: The converged skill of the trained model is better than it otherwise would be.
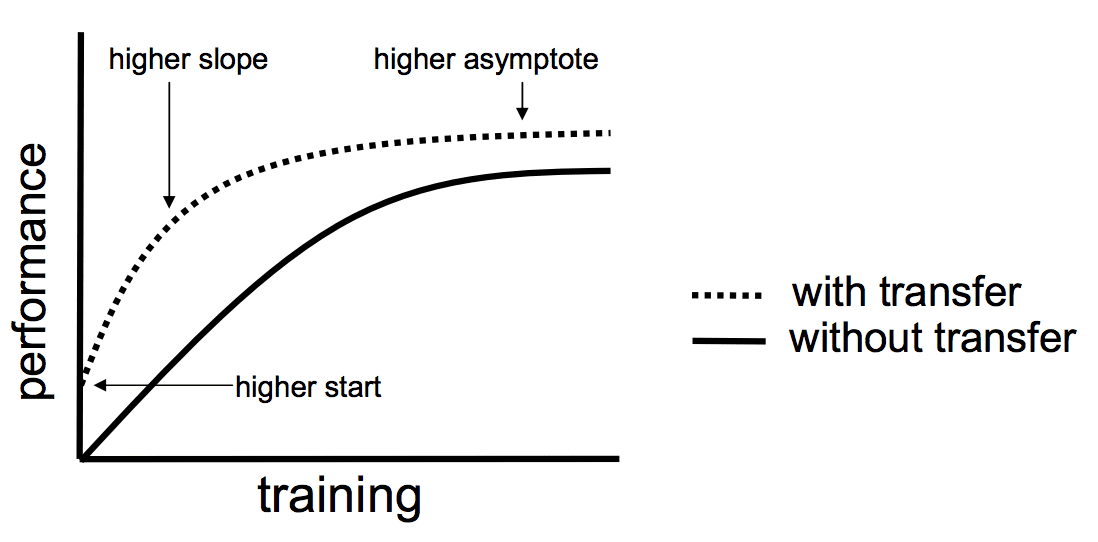
Transfer Learning Benefits
- There are 2 most important factor of using Transfer Learning or not:
- Dataset size: Small or Large
- Similarity of the problem being solved: Similar or Different
- There are 4 cases of using Transfer Learning:
- Small Dataset, Similar Problem: Use the pre-trained model as a fixed feature extractor.
- Our data is small so when fine-tuning the whole model, we will lose the features learned from the pre-trained model. Therefore, we should only use the pre-trained model as a fixed feature extractor.
- The problem is similar so the features learned from the pre-trained model are general.
- Small Dataset, Different Problem: Should not use pre-trained model because:
- The features learned from the pre-trained model are not general and we don’t have enough data to fine-tune the pre-trained model.
- Large Dataset, Similar Problem: Fine-tune the pre-trained model.
- Because the data is large, we can fine-tune the pre-trained model without overfitting.
- For faster training, we can freeze the early layers of the pre-trained model and only fine-tune the later layers first. Then, we can unfreeze the early layers and fine-tune the whole model.
- Large Dataset, Different Problem: We should train the model from sratch, but it will be better if we initialize the weights of the model with the weights of the pre-trained model.
- Small Dataset, Similar Problem: Use the pre-trained model as a fixed feature extractor.
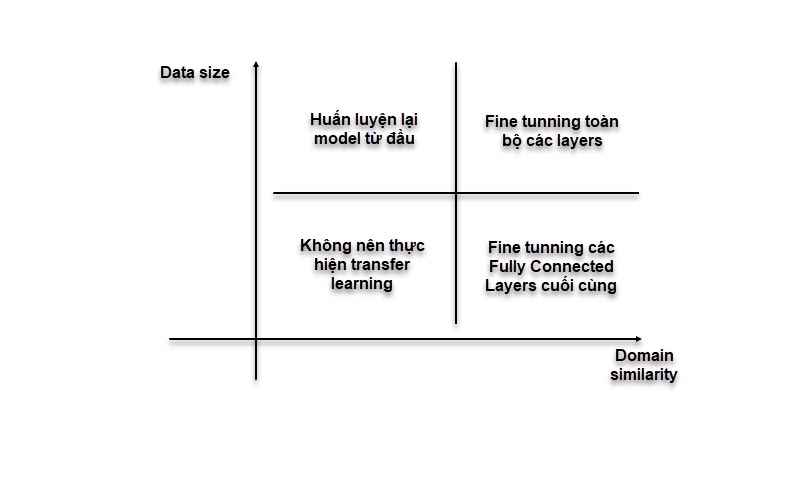
4 cases of using Transfer Learning
4. Notice
Because the pre-trained model is trained on a different dataset, the input of the pre-trained model is different from the input of our model. Therefore, we need to do some preprocessing to the input of the pre-trained model to make it suitable for our model.
We should use a smaller learning rate for the pre-trained model than the learning rate of the new layers. Because the pre-trained model is already trained, we don’t want to change its weights too much. We just want to change the weights of the new layers.